
Cloud Native computing moves fast and changes constantly. The Secure Production Identity Framework for Everyone (SPIFFE) has emerged as a crucial standard for establishing a secure, consistent, and scalable identity for workloads. This open standard offers a streamlined approach to ensuring secure identity verification across workloads and infrastructure.
In this blog post, I'll discuss how SPIFFE can solve the "secret zero" (otherwise known as the "bottom turtle") problem.
What is the “secret zero” problem?
The term “secret zero” refers to the first credential (or initial secret) on your system that is used to gain access to external resources (e.g. other microservices, databases, cloud services).
Think of it like the master key that gains you access to all the resources you require. In that current world, in most cases, that master key will gain you access to a secret manager that, on its own, contains all the credentials that you require to make external connections. If that master key were compromised, all the secrets contained within the secrets manager would similarly be jeopardised. An initial identity that can authenticate your workloads to external services securely, consistently, and scalable is critical, especially in a zero-trust architecture.
SPIFFE basics
At its heart, SPIFFE provides a common framework for identifying and authenticating applications, workloads, and service identities. This advantage allows SPIFFE to be used for workload-to-workload authentication and authorization. This framework relies on each service or workload being associated with a unique SPIFFE Identity (or SPIFFE ID) verified using cryptographic materials.
Challenges solved by SPIFFE
Implementing SPIFFE fundamentally transforms how machine identities are managed and verified:
- Eliminates Secrets Managers: By using SPIFFE, you remove the need for retrieving secrets like API keys, usernames & passwords from the secrets manager but use your SPIFFE identity to authenticate and authorize external services like workloads and databases.
- Cross-Cloud authentication: Use a SPIFFE identity to access cloud services from another cloud provider. An example is using your SPIFFE identity to access an AWS S3 bucket directly from Azure without requiring AWS access tokens.
- CI/CD security: Provide a unique SPIFFE identity for each step in your CI/CD pipeline that can be used to sign artefacts like binaries, SBOMs, and other generated provenance. Signing artefacts allows for cryptographic verification down the line and provides a reliable auditing mechanism.
5 steps to building trust with SPIFFE
The SPIFFE specification consists of multiple components. Over the next five steps, we will use an example application architecture diagram to explain all the different parts of the specification and what each part does.
Step 1: The status quo
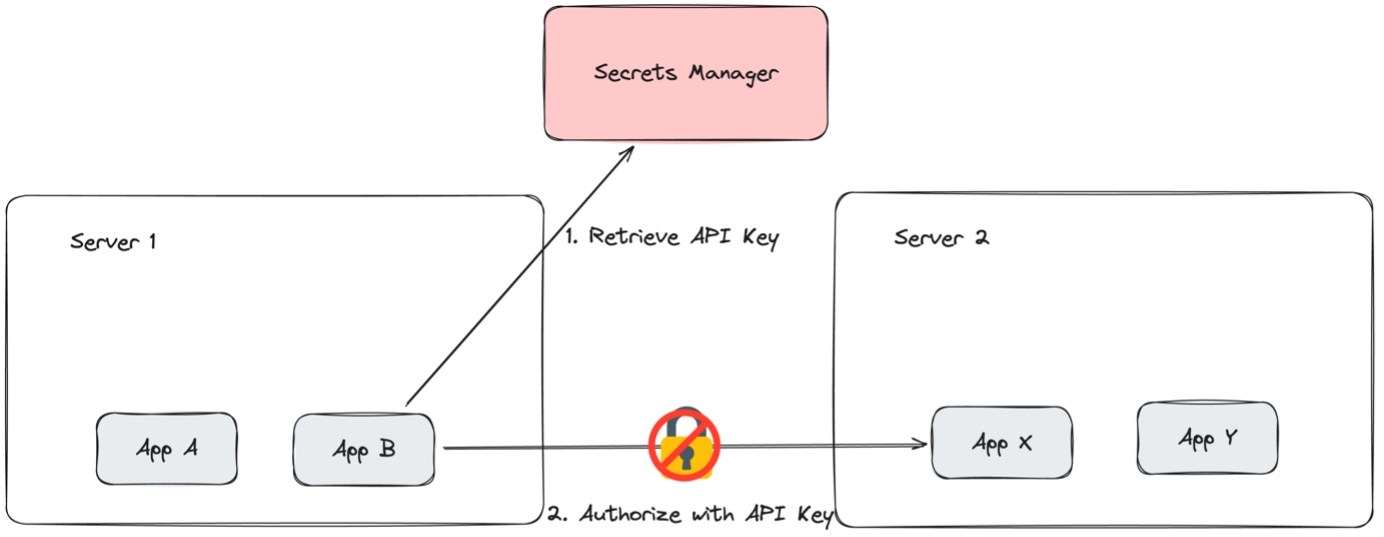
Here, a traditional application (App B) wants to communicate with another application (App X). But it must first retrieve an API key from our secrets manager.
Once App B has retrieved that API key from the secrets manager, it will use it to communicate with App X. App X, on the other hand, will validate that API key and authorize App B to retrieve information from App X.
Because an API key isn’t a cryptographic identity, this connection isn't mTLS-secured or even encrypted. App X only validates a client ID. If an API key is shared between different applications, it can’t explicitly validate the specific application.
Step 2: SPIFFE Identity (SPIFFE ID)
A SPIFFE Identity or SPIFFE ID can be compared to what we are called as humans. It allows us to distinguish ourselves from each other and uniquely identify ourselves. In the case of a SPIFFE ID, it will enable us to identify our workloads with unique names. A SPIFFE ID consists of the following standards:
- A Standard scheme to identify what follows will be a SPIFFE ID
- A Trust domain that uniquely identifies your environment. A company can have multiple separate trust domains. An example is having a trust domain for development and one for production.
- The path that identifies your workload. The path can be something meaningful that is humanly readable, or it can be a randomly generated unique UID
An example SPIFFE ID is spiffe://venafi.com/dc1/node10/frontend/webserver
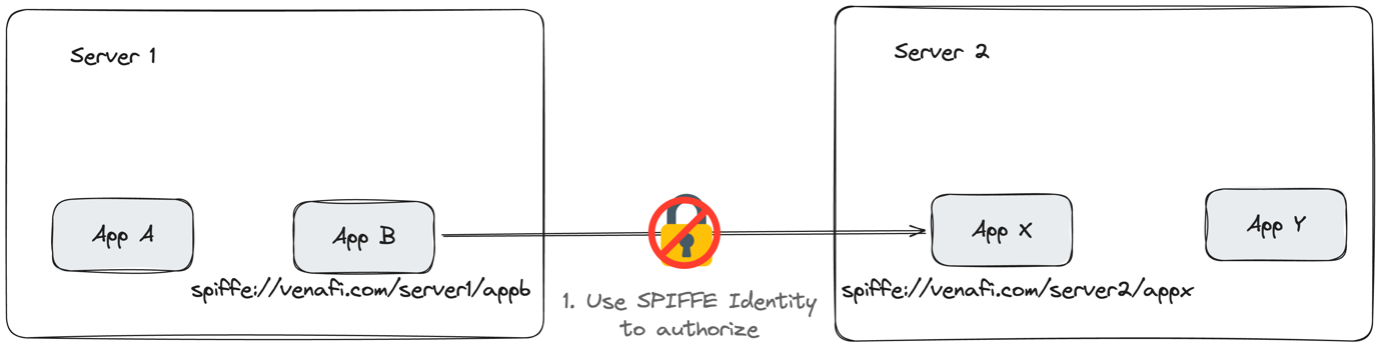
Back to our application, we have removed the secrets manager, and we can now use our SPIFFE ID to authorize the connection. Instead of sending the API key, we send the SPIFFE ID.
App X can authorize the connection as the SPIFFE Identity is unique for application B, and we can be sure the SPIFFE ID isn’t shared with any other application. We only have an identity and no way to prove it; we require cryptographic proof. Because of this, the connection is still not mTLS-secured.
Step 3: SPIFFE Verifiable Identity Document (SVID)
You can think of a SPIFFE Verifiable Identity Document or SVID like a passport, which you would use to get verified at Customs or Border Control.
It is a cryptographically signed identity document used to verify the identity of a workload within a specific trust domain. It aims to standardize identification and authentication for services in distributed, dynamic environments, such as microservices architecture and cloud-native applications.
JWT tokens and X.509 certificates are supported as cryptographic key materials. Those two major cryptographic verification types allow end-users to meet almost all their use cases. The cryptographic key materials for SPIFFE identities should be short-lived (between 1 and 24 hours maximum). In case of compromise of an SVID, the potential blast radius will be reduced.
This is an example of an X.509 certificate:
Certificate:
Data:
Version: 3 (0x2)
Signature Algorithm: sha256WithRSAEncryption
Issuer: O = Venafi, CN = venafi.com L = cluster 1
...
X509v3 extensions:
X509v3 Subject Alternative Name:
URI:spiffe://venafi.com/dc1/node10/frontend/webserverThe SPIFFE ID is represented in the Subject Alternative Name of the extensions section of the certificate. We can also see that our SVID has been signed by a trusted CA (more on the CA later).
Similarly, here is a JWT token example:
JWT Header:
{
"alg": "RS256",
"typ": "JWT"
}
JWT Payload:
{
"spiffe_id": "spiffe://venafi.com/dc1/node10/frontend/webserver",
"iss": "SPIFFE Intermediate CA",
"sub": "dc1/node10/frontend/webserver",
"aud": "https://api.example.com",
"exp": 1679760000,
"iat": 1679760000
}
JWT Signature: <Digital Signature>Let's return to our application. This time, we'll use an SVID in the form of an X.509 certificate instead of just a SPIFFE SVID. When App B initiates a connection to App X by sending over its public key of the SVID, App X will authorize and validate that public key based on the CA chain it's aware of and allow the connection.
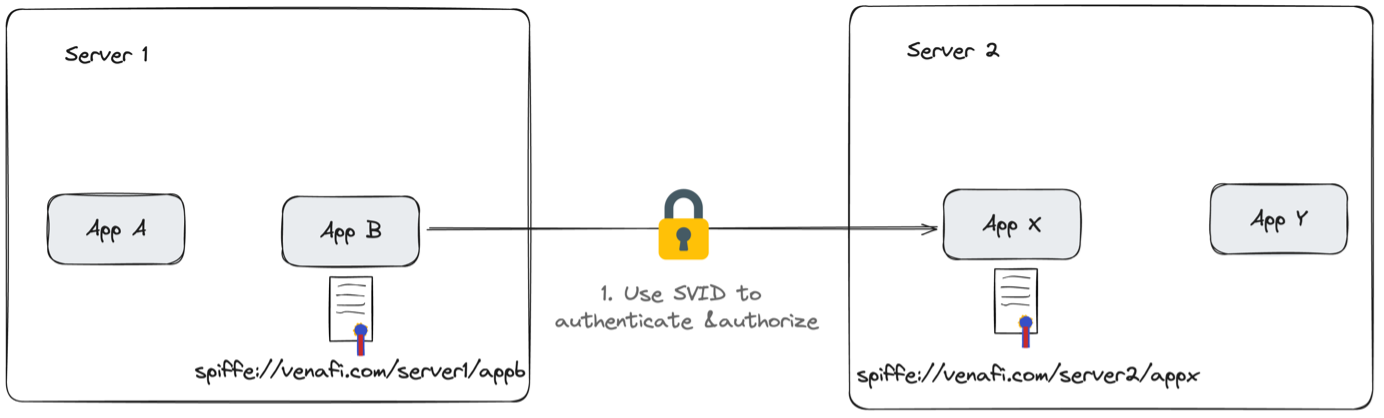
With this step, we've solved authentication, authorization, and auditing. Our connection is also mTLS secure because it uses cryptographic keys. But we're not quite there yet.
Step 4: SPIFFE Workload API
Being able to use a SPIFFE ID and cryptographically ensuring them as SVID alone is not enough. We need to ensure our applications can receive SVIDs from a central system in a trustworthy way.
This is where the SPIFFE Workload API comes in. It is like requesting a passport at the passport office; we need a way to retrieve SVIDs for each workload. This is done through a standardized API called the Workload API.
The workload API should run through a Unix Domain Socket (UDS), making it only locally available for workloads running on the node and not externally. If a UDS is not possible, at least the workload API should only be made available on a localhost networking connection to deny access from the outside world. This is required as the API endpoint is unauthenticated. As part of making this API endpoint, the encompassing agent is also responsible for attesting and validating the workloads. Later in this blog post, we will go into more detail on how it works. The API endpoint needs to be unauthenticated. Otherwise, we wouldn’t solve the ’Secret Zero’ problem!
The workload API allows applications to have a standardised way of retrieving the latest SVIDs in either JWT or X.509 format and retrieving trust bundles that can be used to validate connections. Native Software Development Kits (SDKs) exist for languages like Golang or Java. Even proxies like Envoy or ProxySL can retrieve SVIDs from a workload API.
Hopefully, in the future, we will reach a point where SVIDs are available wherever you run, from AWS Lambda functions to on-prem virtual machines or even mainframes.
Now, back to our application.
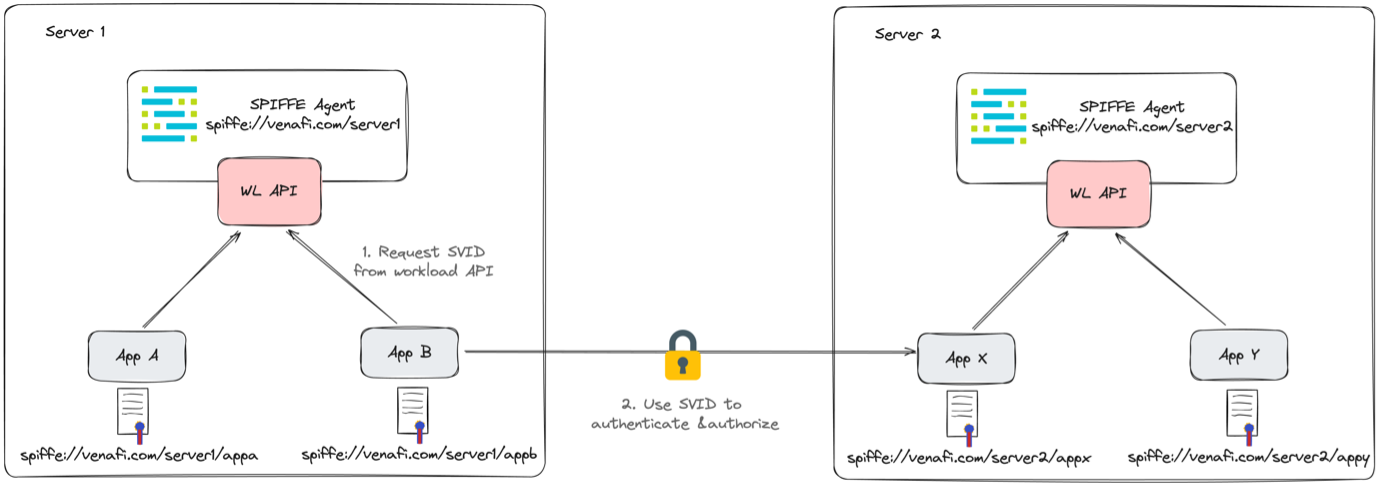
Our architecture has extended a bit, and we are introducing a new component called the SPIFFE agent that exposes the workload API. The SPIFFE agent runs on each node and makes the Workload API available on each node.
This time, App B will request an SVID from the Workload API. In the background, the workload API will validate and attest the workload. Afterwards, it will reply with a signed X.509 SVID to App B. Through an integration, both applications will automatically get the SPIFFE SVID from the Workload API.
From here on out, the exact same steps as outlined in the previous step. The last remaining thing is the attestation and validation of workloads.
Step 5: Attestation and validation
We need to be able to trust that the workloads that run in our environment are trustworthy and can be attested and validated. This verifies that we validate if a workload is what it claims to be.
To start, we must explicitly register workloads with a central SPIFFE server. This can be done manually through a CLI tool or automatically by integrating with the runtime platform (e.g. Kubernetes). Workload registration happens by using environment elements to describe the workload. An example of this can be Kubernetes labels in Cloud Native environments.
Once a workload is registered, we need to be able to validate and attest those workloads. This is done by building up trust in our runtime environment. With SPIFFE, this starts by trusting the node in which a workload runs. This is done by gathering proof of the environment where this node runs, which can be a TPM, Cloud API metadata, or any other information you can trust. The proof gets sent from the SPIFFE agent to the SPIFFE server, which validates that information by gathering its evidence. After it is validated and all found to be correct, the SPIFFE Server issues an SVID to the SPIFFE Agent, allowing the communication between the SPIFFE Server and SPIFFE agent to be authenticated and authorized by mTLS.
After we trust the node, the node can verify the workloads running on that node by using the environment again; for example, Unix, Windows or Kubernetes can be used to achieve this. After this, a workload can be found trustworthy to get an SVID.
As this is abstract, let's refer to our example.
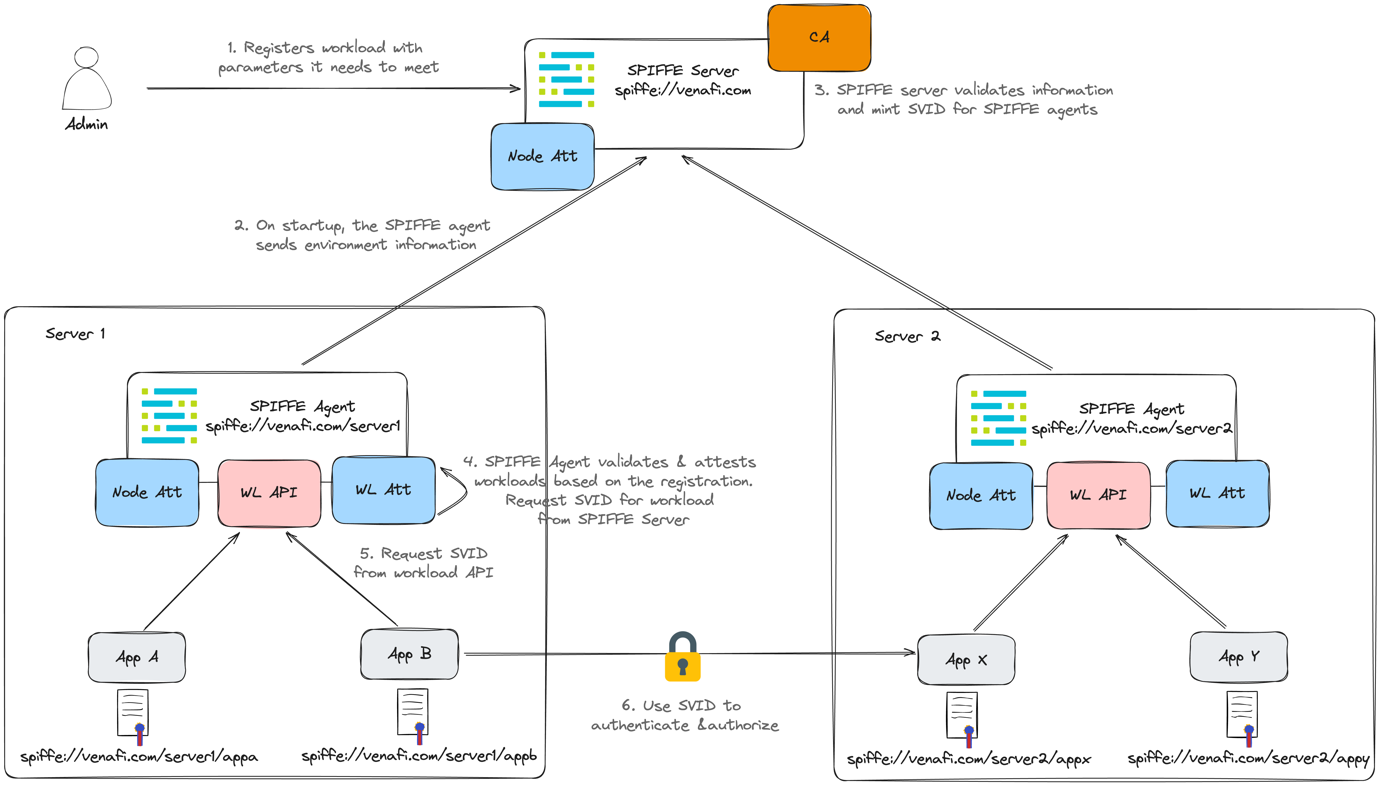
We've added a SPIFFE server with a node attestation endpoint, which is also controlled by our issuing CA. The SPIFFE agents present on each node have a workload attestations endpoint and a node attestations endpoint.
Now, when a SPIFFE agent comes up, it gathers information on the environment where it runs. It returns this proof to the SPIFFE server, which verifies it. If that information is correct, the server issues an SVID for the node and sends it back to the agent. This will be done for all servers where the SPIFFE agent gets deployed.
After the workload is registered with the central SPIFFE Server, the SPIFFE agent will attest and validate the trustworthiness of the workloads that run on that specific node and determine whether a workload should get an SVID.
Once that's done, App B can request an SVID from the agent and use that SVID effectively to authenticate to App X using a SPIFFE identity.
SPIFFE, secret zero and zero trust
That's how the different components of SPIFFE come together to secure the connection, and this is how we solve the true secret zero problem in zero-trust networking.
Your SPIFFE server is the central source of truth because that's where your CA is located and where your root of trust begins.
Use cases for SPIFFE federation
One of the other significant advancements SPIFFE offers is federation, which enables trust across different environments with multiple SPIFFE servers and trust domains.
This functionality can be segmented into three primary use cases:
- Internal segmentation: Different environments within the same company, such as a shared staging and production environment, can benefit from distinct trust domains. It allows us to setup cross-communication through federation between production and shared, shared and development but not directly between production and development.
- Cross-company implementation: You might need to exchange data with another company and thus want to federate your trust domain with another company's trust domain. In many ways, this is the same as a federation within your internal environment. Only in this case, you don’t necessarily know the level of SPIFFE adoption that an external company has.
- Facilitating external consumers: For entities without a SPIFFE setup, federation allows them to effortlessly authenticate callers, bypassing the complexity of a full SPIFFE deployment. This is mostly done through OIDC, and it is essential to establish authentication and authorization with cloud and SAAS providers.
Industry adoption
The SPIFFE specification is gaining recognition, with notable implementations such as SPIRE—the open-source reference implementation of SPIFFE. Moreover, leading cloud providers like Google Cloud, and Azure are integrating SPIFFE into their security architectures.
Software tools, including Istio, cert-manager, HashiCorp Consul and Dapr, have adopted different levels of the SPIFFE specification to implement foundational identity for their workloads, further validating its importance.
SPIFFE stands out as a significant innovation in securing machine-to-machine connections
By providing foundational identity verification, reducing reliance on API keys, and simplifying processes with automation, SPIFFE is transforming industry standards.
With widespread adoption and ongoing enhancements, SPIFFE is poised to remain a pivotal element in Cloud Native security for years to come.
Want to learn more about how to protect your cloud-first, GenAI, post-quantum world?
Join us in Boston for Machine Identity Security Summit 2024, October 1-3!