
Google provides several mechanisms to give workloads accessing Google Cloud (GCP) services an identity. This identity allows Google to authenticate the workload and determine the appropriate permissions to grant it. For workloads running in GCP on GKE, Cloud Run or GCE environments, the recommended practice is to use the Service Account (SA) associated with the service and provide the SA with the permissions required by the workload. Google offers various client libraries that can be imported into your workload code to make it easy for your code to automatically use the associated SA when calling GCP APIs.
However, there are circumstances when using these client libraries is either impossible or undesirable. For example, you might not want to or be able to change the code that is calling GCP APIs - I came across this scenario when using a Grafana data source plugin to call the GCP Asset Inventory API and process the JSON response (sure, I could’ve made the code changes, raised a PR etc, but that seemed like quite some work in a language and codebase I’m not familiar with). This blog will describe an alternative approach using the Google Metadata service and Envoy Proxy to inject a valid authentication token into GCP API requests without requiring changes to the client application code. You can find all the necessary code, configuration and instructions for demoing this approach here.
Background
To call GCP APIs you need to provide a valid Authorization header, e.g. by supplying a valid Bearer token. Here’s a simple example using the gcloud CLI to generate the token and curl to call an API:
$ gcloud auth print-access-token
ya29.a0AXooCgs60OSpeSC-N-J8g6pxdWn0ufLIgSo5o9RNSKZO9t_kklYKv32s9CKg6FKaLh4fsQ_4RUaH8ZGxDe-lBDsYgzbpmYmoyxGX0UYQOoMlQCAW6dGtBW6B2KEGkk9U_TJmjCBJuQKLCG1DyP7C8Mbgd0ibnC32jMqnrqRZ5dEaCgYKASYSAQ8SFQHGX2MiQuqNW29b6ueexxxxx
$ curl -vvv -H "Authorization: Bearer ya29.a0AXooCgs60OSpeSC-N-J8g6pxdWn0ufLIgSo5o9RNSKZO9t_kklYKv32s9CKg6FKaLh4fsQ_4RUaH8ZGxDe-lBDsYgzbpmYmoyxGX0UYQOoMlQCAW6dGtBW6B2KEGkk9U_TJmjCBJuQKLCG1DyP7C8Mbgd0ibnC32jMqnrqRZ5dEaCgYKASYSAQ8SFQHGX2MiQuqNW29b6ueexxxxx" "https://cloudasset.googleapis.com/v1/projects/my-project/assets?assetTypes=assetTypes=storage.googleapis.com/Bucket&contentType=RESOURCE"
These tokens expire after 60 minutes, so this approach is unlikely to be practical or secure except for the occasional one-off API call.
Workloads running in Cloud Run, GKE, or GCE environments have access to Google’s Metadata service (details here) via several endpoints. One of these endpoints, http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/token, returns a JSON response containing a token that can be used as a valid Bearer token in the Authorization header for a GCP API call. NOTE: This service is not accessible outside of GCP. Google documentation about authentication using the Metadata Server is here.
By using a proxy server, such as Envoy Proxy, to intercept and enrich workload calls to GCP APIs, valid tokens can be retrieved from the Metadata service and injected as an Authorization header into the API request before it is forwarded to the real endpoint. The following shows this mechanism in diagrammatic form:
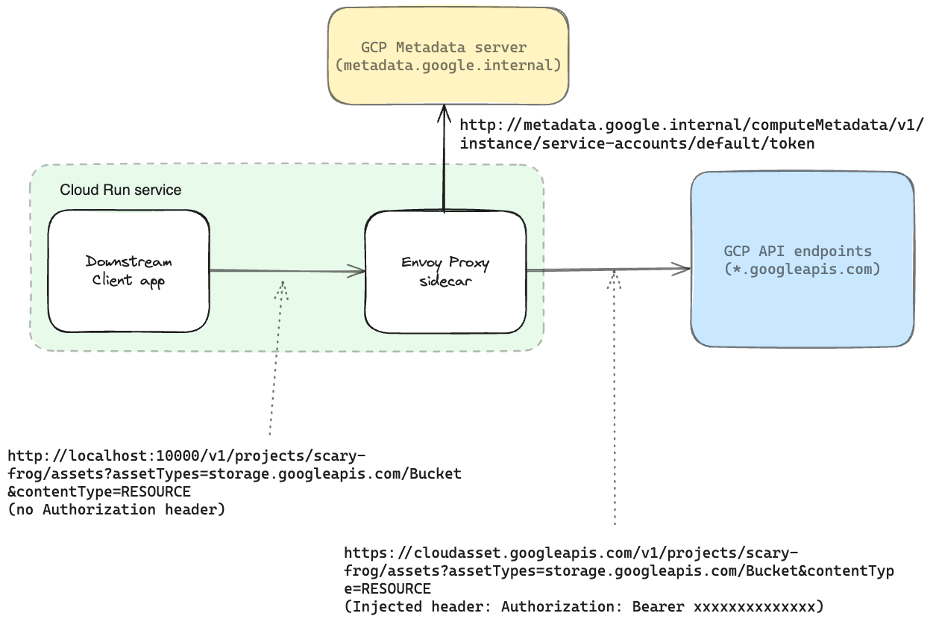
For this demo, I’m using Cloud Run and taking advantage of its support for sidecars, but this same approach could easily be transferred to both GKE and GCE. The downstream client app/workload doesn’t call the GCP API directly, instead it sends the request to the Envoy Proxy sidecar. Envoy has been configured to intercept every inbound request and call the token endpoint of the Metadata service for each. The token value is extracted from the response and added to the request as the ‘Authorization: Bearer xxxx’ header before the request is forwarded to the appropriate GCP endpoint. The response from the Metadata service is a JSON payload containing several values; this adds extra complexity as Envoy needs to extract this token value first.
Exploring the demo application
There are two demos included in the repo:
- Local: run this in your local environment using Docker Compose
- Cloud Run: run as a single Cloud Run service in GCP
Both demos require a custom Envoy Proxy image (the explanation for this is later in this blog), and the Cloud Run one also requires the Python ‘api-client’ built into an image. As mentioned earlier, GCP’s Metadata server is not accessible outside of GCP so the Local demo includes a mock Metadata server (which still generates genuine tokens).
The repo contains Dockerfiles for both these images and cloudbuild.yaml files to enable them to be built using GCP Cloud Build.
To run both demos a valid GCP account is necessary, and specific GCP APIs must be enabled. For detailed instructions on how to prepare and run the demos, please refer to the repo’s README.
Breakdown of the Envoy Proxy configuration
Envoy Proxy is best known as an essential component in many service mesh architectures, such as Istio, but it can also be used as a standalone proxy server instead of, say, nginx. It has a mostly deserved reputation for having a steep learning curve, which, given its rich feature set, is understandable and mitigated by impressive documentation and comprehensive examples on its documentation site.
Each of the demos contains a yaml file which specifies the Envoy configuration. Although the two are slightly different, the main aspects are the same and these are described in more detail below.
Envoy divides hosts into upstream and downstream ones. Downstream hosts connect to Envoy via Listeners and send it requests to process and forward to upstream hosts. These upstream hosts (configured as Clusters in Envoy) receive requests from Envoy and return responses which are processed and then returned to the downstream hosts.
Clusters
In the cluster section of the config file, a cluster is configured for each endpoint Envoy connects to, e.g. the Metadata service and the different GCP API endpoints:
clusters:
- name: metadata_server
type: LOGICAL_DNS
dns_lookup_family: V4_ONLY
connect_timeout: 2s
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: metadata_server
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: "metadata.google.internal"
port_value: 80
Listeners
In the listeners section of the config file there are standard filters for handling the HTTP connections and routing the requests, plus a Lua filter containing inline Lua code which is executed against each request received from a downstream client. This code is contained within the envoy-on-request function:
http_filters:
- name: envoy.filters.http.lua
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.lua.v3.Lua
default_source_code:
inline_string: |
function envoy_on_request(request_handle)
First, a request is defined and sent to the metadata-server cluster, i.e. the Metadata server endpoint:
local request_options = {
["asynchronous"] = false,
["timeout_ms"] = 2000,
["send_xff"] = false
}
local headers, body = request_handle:httpCall(
"metadata_server",
{
[":method"] = "GET",
[":path"] = "/computeMetadata/v1/instance/service-accounts/default/token",
[":authority"] = "metadata.google.internal",
["metadata-flavor"] = "Google"
},
"",
request_options
)
The request_handle:httpCall is documented here - what is not obvious is method, path and authority are mandatory values. The metadata-flavor header (with a value of ‘Google’) is necessary otherwise the service will respond with a 403 status. Likewise, Envoy should not include the x-forwarded-for header in its request to the Metadata server (sent by default), otherwise a 403 status will be returned - this is prevented by setting send_xff to false in the request options.
There is some logging code, included to show how to output to stdout the contents of the returned headers and body.
request_handle:logInfo("Headers:")
for i,v in pairs(headers) do
request_handle:logInfo(i)
request_handle:logInfo(v)
end
request_handle:logInfo("Body:")
request_handle:logInfo(body)
Finally, a Lua JSON library, cjson, is used to retrieve the contents of the access_token property from the response body. This value is added to the original downstream client request, as the Authorization header, before the request is forwarded to the appropriate API endpoint cluster as per the defined routing rules.
local json=require("cjson")
local response_body = json.decode(body)
if response_body and response_body.access_token then
request_handle:headers():add("Authorization", "Bearer " .. response_body.access_token)
end
The cjson library is not included by default in the official Envoy container image; this is why we need to build a custom image (which uses Luarocks to install the library as part of the image build process).
API quotas warning
Be aware that calls to the Metadata API are subject to quotas; according to Google documentation:
- For Cloud Run and GCE, requests that exceed 50 queries per second might be rate-limited (details here)
- For GKE, the Metadata server runs as a Daemonset in the cluster and each Pod in this Daemonset limits the number of connections to 200 (details here).
The access token generated by the Metadata server is valid for 60 minutes and it caches it, meaning multiple calls to the token API within this 60-minute period will return the same token value. If you decide it is likely that you will have sufficient traffic to exceed the above quotas then it is possible to add a token caching mechanism into your Envoy Proxy configuration.
When our experts are your experts, you can make the most of Kubernetes
Wrap Up
For the demo code, config files and instructions on how to run the demos see: https://github.com/jetstack/envoy-workload-identity.
As the blog shows, Workload Identity in Google Cloud can be achieved with a straightforward solution that doesn’t require any code changes. Furthermore, I’ve found Envoy Proxy to be a powerful and well-documented proxy solution which I look forward to using again in the future.
Steve is Jetstack Consult’s Technical Director with a focus on helping organisations get the most out of their investment in cloud native technologies.